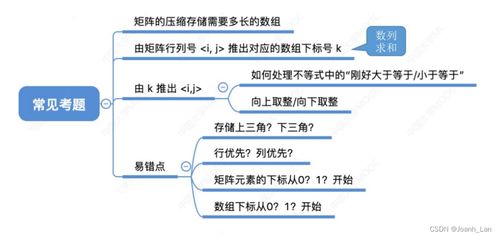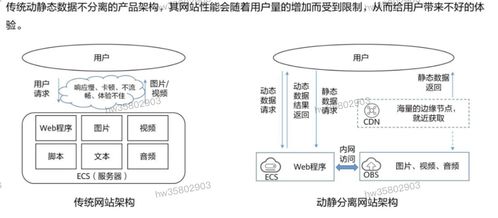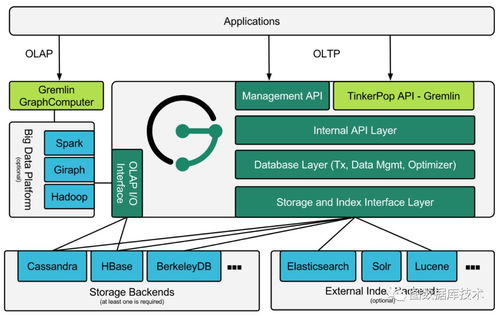
隨著大數據時代的到來,海量數據的存儲、處理和分析成為企業和開發者面臨的核心挑戰。對象存儲(Object Storage Service, OSS)以其高可擴展性、高可靠性和低成本的優勢,已成為數據湖架構的基石。在此之上,構建一個集成的智能數據分析處理框架,能夠極大地提升數據價值挖掘的效率和深度。
一、 核心框架:對象存儲OSS作為統一數據湖
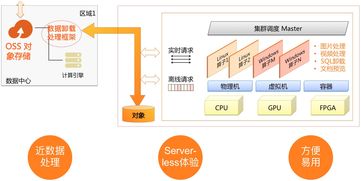
該框架的核心是將OSS定位為企業的統一數據湖。所有原始數據、中間處理結果和最終分析數據都存儲在OSS中,形成一個單一、可擴展的真相源。其優勢在于:
- 無限擴展:存儲容量可隨數據增長無縫擴展,無需預先規劃。
- 成本低廉:采用按需付費模式,冷熱分層存儲進一步優化成本。
- 高持久性:提供高達99.9999999999%(12個9)的數據持久性,保障數據安全。
- 開放兼容:支持標準API(如S3協議),便于各類數據處理工具直接訪問。
二、 智能數據處理功能與服務
基于OSS的數據湖,框架提供分層、自動化的數據處理流水線,涵蓋從數據攝入到智能洞察的全過程。
1. 數據接入與預處理服務
- 多源異構數據接入:支持從數據庫、日志文件、IoT設備、應用程序等實時或批量將數據寫入OSS。利用OSS的SDK、命令行工具或可視化客戶端輕松完成。
- 自動化數據預處理:集成無服務器計算服務(如AWS Lambda、阿里云函數計算FC),通過事件觸發器(如OSS文件上傳事件)自動觸發數據清洗、格式轉換(如JSON、Parquet、ORC)、壓縮和分區操作,為后續分析做好準備。
2. 彈性計算與數據處理引擎
- 查詢加速與元數據管理:結合數據目錄服務(如AWS Glue Data Catalog、阿里云DataWorks),自動爬取OSS中的數據并建立元數據,支持表結構定義。通過索引和緩存技術加速查詢。
- 無服務器化數據處理:利用云原生的大數據服務(如AWS EMR Serverless、阿里云EMR on ACK)或交互式查詢服務(如AWS Athena、阿里云DataLake Analytics),直接對OSS中的數據進行SQL查詢、批處理(Spark、Flink)和流處理,無需管理底層集群,實現真正的彈性伸縮。
3. 高級分析與AI集成
- 機器學習與模型訓練:將OSS作為特征庫和訓練數據源,直接與機器學習平臺(如AWS SageMaker、阿里云PAI)集成。支持從數據準備、模型訓練、評估到部署的全流程,生成的模型可再次存入OSS。
- 智能內容處理:利用與OSS無縫集成的AI服務(如阿里云智能媒體管理IMM、AWS Rekognition),自動對存儲的圖片、視頻、文檔進行內容分析(如標簽識別、人臉分析、文本抽取),并將結構化結果寫回OSS,豐富數據維度。
4. 統一的數據治理與安全
- 生命周期管理:基于策略自動將數據在不同存儲層級(標準、低頻、歸檔)間移動,優化性能和成本。
- 細粒度權限控制:通過Bucket Policy、RAM策略或STS臨時授權,精確控制何人、何應用在何種條件下訪問哪些數據。
- 審計與監控:記錄所有數據訪問和操作日志,并集成監控告警服務,保障數據處理的合規性與可觀測性。
三、 典型應用場景與價值
- 日志分析與運營監控:將應用、服務器日志實時存入OSS,通過無服務器查詢服務快速分析錯誤趨勢、用戶行為。
- 物聯網(IoT)數據分析:海量設備數據寫入OSS,利用流處理框架進行實時風控、預測性維護。
- 推薦系統與用戶畫像:將用戶行為數據沉淀至OSS數據湖,結合機器學習服務訓練和更新推薦模型。
- 多媒體內容智能管理:自動對海量圖片/視頻進行AI打標、分類,構建可搜索的多媒體資產庫。
###
基于對象存儲(OSS)的智能數據分析處理框架,成功地將低成本、高可靠的數據存儲與彈性、智能的數據處理能力相結合。它打破了數據孤島,提供了一條從原始數據到商業洞察的敏捷、高效的路徑。通過充分利用云原生的無服務器計算和AI服務,企業能夠以更低的運維成本和更快的創新速度,應對日益復雜的數據挑戰,真正實現數據驅動的智能決策。