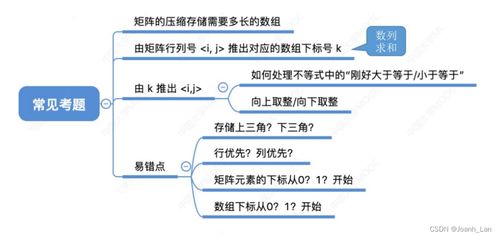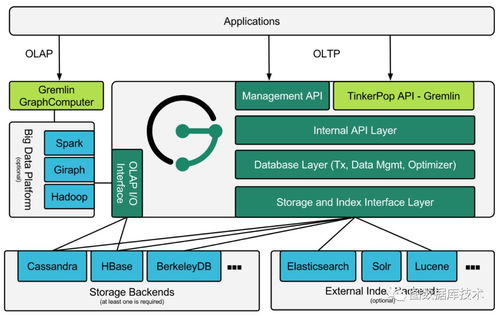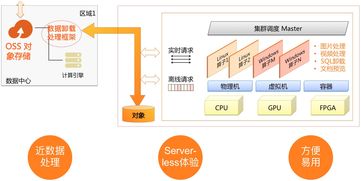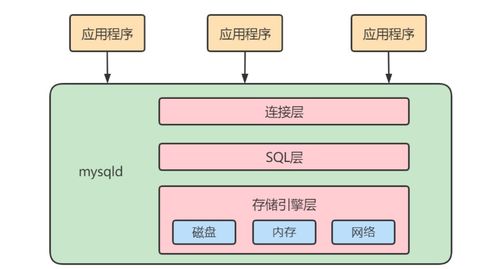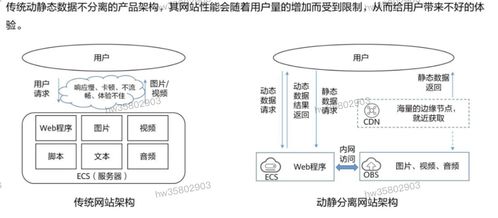
在HCIP存儲服務規劃的學習中,數據處理與存儲服務是確保數據價值有效釋放和業務連續性的核心環節。本章節將重點探討數據處理流程設計、存儲服務選型策略以及典型場景下的架構實踐。
一、數據處理流程規劃
數據處理通常遵循“采集-傳輸-處理-存儲-應用”的閉環邏輯。在規劃時需明確:
- 數據采集層:確定數據來源(業務數據庫、日志、IoT設備等),設計實時/批量采集策略,并考慮格式統一與初步過濾。
- 數據傳輸層:根據延遲和帶寬要求,選擇消息隊列(如Kafka)、數據同步工具或直連傳輸,保障數據流動的可靠性與安全性。
- 數據處理層:部署流處理(如Flink)或批處理(如Spark)引擎,實現數據清洗、轉換、聚合等操作,為存儲與分析做準備。
- 質量控制:建立數據校驗、去重與異常監測機制,確保進入存儲的數據合規可用。
二、存儲服務選型策略
存儲服務需匹配數據處理目標與業務特征:
- 在線事務處理(OLTP)場景:選用關系型數據庫(如MySQL、PostgreSQL),注重ACID特性與高并發讀寫能力。
- 在線分析處理(OLAP)場景:面向海量數據分析,可選數據倉庫(如ClickHouse、Hive)或OLAP數據庫,優化復雜查詢性能。
- 非結構化數據場景:對象存儲(如AWS S3、華為云OBS)適用于圖片、視頻等大文件;文檔數據庫(如MongoDB)適合半結構化JSON數據。
- 緩存與加速場景:引入Redis或Memcached作為熱數據緩存層,減輕后端存儲壓力,提升響應速度。
三、典型架構實踐
- 混合云數據湖架構:
- 將原始數據統一存入對象存儲構建數據湖,保留原始格式。
- 通過數據處理服務轉換后,將結構化的結果存入數據倉庫供BI工具分析。
- 優勢在于兼顧靈活性與成本,支持多源數據長期留存與按需計算。
- 實時數據處理流水線:
- 采集端數據實時寫入消息隊列,流處理引擎進行實時計算。
- 計算結果同步寫入時序數據庫(如InfluxDB)用于監控儀表盤,同時備份至對象存儲供后續回溯。
- 適用于IoT監控、實時風控等低延遲場景。
- 存儲分層設計:
- 根據數據熱度實施分層策略:熱數據存于高性能SSD,溫數據存于標準云硬盤,冷數據歸檔至廉價對象存儲或磁帶庫。
- 結合生命周期管理策略自動遷移數據,優化總體擁有成本(TCO)。
四、關鍵考量點
- 一致性權衡:根據業務容忍度選擇強一致性(如金融交易)或最終一致性(如社交動態)。
- 擴展性設計:采用分庫分表、讀寫分離或分布式存儲(如Ceph)支撐業務增長。
- 災備與高可用:通過跨可用區部署、數據多副本及定期備份保障數據持久性。
- 安全合規:實施數據加密(傳輸/靜態)、訪問控制及審計日志,滿足行業監管要求。
數據處理與存儲服務規劃需以業務需求為錨點,通過合理的技術選型與架構設計,構建高效、可靠且經濟的數據管線。實際落地中應持續評估性能指標與成本效益,并隨業務演進迭代優化。