引言
在計算機科學與數據處理領域,矩陣(二維數組)是表示數據關系(如圖像像素、網絡拓撲、方程組系數)的常用結構。許多實際應用中的矩陣具有“特殊”性質,例如大量元素為零(稀疏矩陣),或元素分布呈現規律性(如對稱矩陣、三角矩陣、對角矩陣等)。若直接使用二維數組存儲這些矩陣,會浪費大量存儲空間并降低處理效率。因此,“特殊矩陣的壓縮存儲”技術應運而生,它通過只存儲非零或關鍵元素,并利用數學映射關系恢復原矩陣結構,從而顯著節省存儲空間并提升計算性能。本文將探討常見特殊矩陣的壓縮存儲原理,并分析其在現代數據處理與存儲服務中的關鍵作用。
常見特殊矩陣的壓縮存儲方法
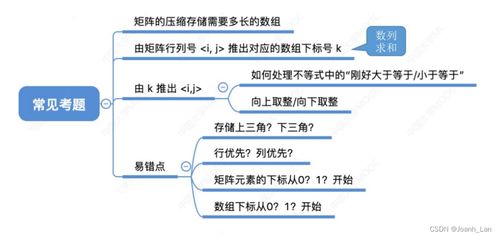
1. 對稱矩陣與三角矩陣
對于一個n階方陣,若元素滿足a{ij} = a{ji},則為對稱矩陣。其下三角(或上三角)區域即可完整表示整個矩陣。壓縮存儲時,通常將下三角(包括對角線)的元素按行優先(或列優先)順序存入一個一維數組SA[0..n(n+1)/2-1]中。元素a_{ij}(i≥j)在數組中的位置k可通過公式(如行優先:k = i*(i+1)/2 + j)計算。上三角矩陣原理類似。
2. 對角矩陣與帶狀矩陣
對角矩陣是所有非零元素都集中在主對角線及其附近幾條對角線上的矩陣。例如三對角矩陣(非零元素僅出現在主對角線及其上下相鄰對角線)。對于n階三對角矩陣,只需存儲3n-2個非零元素,通常按行優先存入一維數組,并通過映射關系(如a_{ij}對應到數組下標k=2i+j)訪問。此方法可擴展至更寬的帶狀矩陣。
3. 稀疏矩陣
稀疏矩陣是零元素占比極高的矩陣,其壓縮存儲最具代表性。常用方法有:
- 三元組順序表:存儲每個非零元素的行、列和值,構成一個(row, col, value)的三元組列表。結構簡單,但進行矩陣運算(如轉置)時效率可能不高。
- 行邏輯鏈接的順序表:在三元組基礎上增加行起始位置信息,便于按行快速訪問。
- 十字鏈表:每個非零元素作為一個節點,包含行、列、值以及指向同行和同列下一個非零元素的指針。它靈活支持矩陣的動態變化(如插入、刪除),但存儲開銷略大。
壓縮存儲的優勢與挑戰
優勢:
1. 大幅節省存儲空間:這是最直接的收益,尤其在處理大規模科學計算(如有限元分析)、圖像處理或推薦系統(用戶-物品評分矩陣)時,能減少內存和磁盤占用。
2. 提升計算效率:許多算法(如矩陣乘法、迭代求解)可被優化為只對非零元素進行操作,減少不必要的零值計算,從而加速處理。
3. 降低I/O開銷:在磁盤或網絡傳輸中,數據量減少意味著更快的讀寫速度和更低的帶寬消耗。
挑戰:
1. 訪問開銷:隨機訪問元素a_{ij}可能需通過公式計算或鏈表遍歷,比直接數組索引慢。
2. 算法復雜性增加:實現矩陣運算時,邏輯變得復雜,需精心設計以保持效率。
3. 動態修改成本:對于某些靜態壓縮格式(如三元組順序表),插入或刪除非零元素可能引起大規模數據移動。
在數據處理與存儲服務中的應用
現代數據處理與存儲服務(如分布式數據庫、大數據分析平臺、云存儲)廣泛依賴高效的數據結構來管理海量信息。特殊矩陣的壓縮存儲技術在其中扮演著重要角色:
- 大規模科學計算與工程仿真:在氣候建模、流體動力學等領域的數值計算中,系數矩陣往往是大型稀疏矩陣。使用壓縮存儲(如CSR - Compressed Sparse Row格式)是高性能計算(HPC)庫(如Intel MKL、PETSc)的標配,它們運行在分布式存儲系統上,有效利用集群內存和計算資源。
- 機器學習與數據挖掘:推薦系統、自然語言處理中的詞袋模型等常產生高維稀疏特征矩陣。壓縮存儲使得這些矩陣能夠被加載到內存中進行快速訓練(如使用LIBFM、XGBoost等庫)。在分布式計算框架(如Apache Spark)中,稀疏矩陣格式被用于高效處理RDD或DataFrame。
- 圖數據處理:圖(如社交網絡、知識圖譜)的鄰接矩陣或關聯矩陣通常是稀疏的。圖數據庫(如Neo4j)和圖計算引擎(如Apache Giraph、GraphX)在內部使用壓縮稀疏結構存儲圖數據,以支持快速的圖遍歷和查詢。
- 數據庫與數據倉庫:一些列式存儲數據庫(如MonetDB)或大數據格式(如Apache Parquet)會采用類似壓縮思想,對重復值或零值進行編碼壓縮,減少存儲占用并加速掃描查詢。例如,存儲一個大部分為零的用戶行為矩陣時,只記錄非零事件。
- 圖像與多媒體存儲:雖然圖像像素矩陣通常稠密,但在特定變換域(如離散余弦變換后)或表示掩模、Alpha通道時,可能產生稀疏或規則結構,壓縮存儲有助于減少文件大小(如在某些專業圖像格式中)。
與展望
特殊矩陣的壓縮存儲是數據結構優化在實踐中的經典體現。它通過洞察數據的內在規律,在存儲空間與訪問效率之間取得平衡。隨著大數據和人工智能時代的到來,數據規模持續膨脹,結構愈發復雜,對高效存儲與處理的需求只增不減。壓縮存儲技術將繼續與分布式系統、新型硬件(如非易失性內存)、智能壓縮算法(結合機器學習預測數據模式)深度融合,為數據處理與存儲服務提供更強大、更智能的底層支撐。理解和掌握這些基礎數據結構,對于設計高效、可擴展的數據系統至關重要。