圖數據庫作為一種專門用于存儲和處理圖結構數據的數據庫,在處理復雜關系、社交網絡、推薦系統、欺詐檢測等領域展現出巨大優勢。在開源圖數據庫領域,TitanDB及其繼任者JanusGraph是重要的技術選擇。本文將系統性地介紹其入門知識、實戰、選型對比,并深入分析其存儲結構與數據處理服務。
一、入門簡介:從TitanDB到JanusGraph
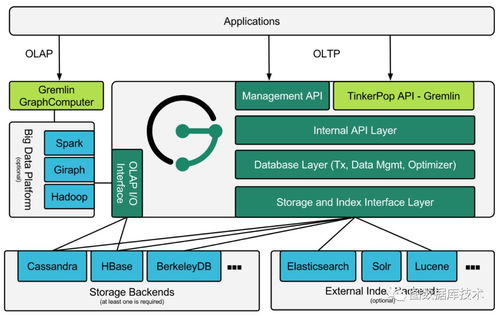
TitanDB 是一款早期開源的分布式圖數據庫,支持處理超大規模的圖和并發事務。其核心特性包括支持Gremlin圖遍歷語言、分布式架構、以及可插拔的后端存儲(如Cassandra, HBase)與索引引擎(如Elasticsearch, Solr)。隨著開發逐漸停滯,其社區分支演化為 JanusGraph。
JanusGraph 繼承了TitanDB的核心代碼與架構,并在Linux基金會的支持下持續發展。它增強了分布式圖計算的擴展性、完善了社區生態,并提供了更活躍的維護。對于新項目,通常建議直接采用JanusGraph作為技術選型。
入門JanusGraph,首先需理解其核心組件:圖實例(Graph)、圖遍歷源(GraphTraversalSource)以及Gremlin查詢語言。一個簡單的本地部署可能涉及配置一個后端存儲(如BerkeleyDB用于測試)并啟動Gremlin Server。
二、實戰關鍵步驟與常見模式
- 環境搭建與配置:生產環境通常選擇分布式后端,如Cassandra或HBase作為存儲層,Elasticsearch作為索引層。配置文件的優化(如緩存設置、連接池)對性能至關重要。
- 數據建模:圖數據庫建模的核心是頂點(Vertex)、邊(Edge)和屬性(Property)。需要仔細設計頂點標簽、邊標簽及屬性鍵,考慮查詢模式,避免超級節點問題。
- 數據導入:批量導入推薦使用
GraphOfTheGodsFactory類似的工具或編寫Gremlin腳本進行批量處理,注意在導入過程中合理使用事務和批量提交以提高效率。 - 查詢與遍歷:熟練掌握Gremlin語法是關鍵。例如,查找某人的朋友的朋友:
g.V().has('name','Alice').out('friend').out('friend').values('name')。應利用索引加速屬性查找,避免全圖掃描。 - 運維與監控:監控后端存儲(Cassandra/HBase)的性能指標、JanusGraph自身的指標(如緩存命中率),并定期進行數據備份與圖分析(如計算度中心性)。
三、選型對比:JanusGraph vs. 其他圖數據庫
- 與Neo4j對比:Neo4j是單機主從架構的領先者,擁有極佳的成熟度、友好工具和查詢性能(Cypher語言)。JanusGraph強在分布式擴展性,能處理超大規模圖,但運維復雜度更高。選擇取決于數據規模與團隊技術棧。
- 與Neptune(AWS托管服務)對比:Neptune是基于Titan/JanusGraph思想的云托管服務,簡化了運維但鎖定云廠商。JanusGraph提供更靈活的自托管與多云部署能力。
- 與Dgraph對比:Dgraph是原生分布式圖數據庫,使用GraphQL±查詢語言,在分布式事務和查詢性能上有獨特設計。JanusGraph生態更成熟(兼容TinkerPop棧),社區工具更多。
選型建議:若需處理千億級頂點/邊且團隊有分布式系統運維能力,JanusGraph是強大選擇。若數據量在百億級以下且追求開發效率,Neo4j可能更合適。云原生場景可評估Neptune。
四、存儲結構深入分析
JanusGraph的存儲結構是其分布式能力的基石,采用“鄰接表”的變體進行存儲。
- 數據布局:
- 頂點及其屬性:以頂點ID為鍵,序列化存儲所有屬性。
- 鄰接關系(邊):邊被存儲在起始頂點的序列化數據中,包含邊ID、指向的頂點ID、邊標簽和邊屬性。這種設計使得遍歷頂點的出邊極其高效(一次讀取)。
- 索引數據:為支持按屬性快速查找頂點,屬性索引被單獨存儲在后端(如Elasticsearch)或作為輔助表/列族存儲。
- ID分配與分區:JanusGraph支持自定義頂點ID,或使用其分布式ID分配器(基于后端存儲如Cassandra的輕量級事務)生成唯一、可分區ID。合理的分區策略(如按頂點ID范圍)對負載均衡至關重要。
- 序列化與存儲格式:數據在寫入前被序列化為緊湊格式。存儲后端(如Cassandra)的列族設計直接影響讀寫性能。例如,一個頂點的所有數據可能存儲在Cassandra的一個行鍵下,其鄰接邊作為列存儲。
五、數據處理與存儲服務架構
JanusGraph的架構清晰地將數據處理層與底層存儲服務解耦。
- 數據處理層(JanusGraph Core):
- 事務管理:提供ACID語義的事務,支持多線程并發。事務緩存(Transaction Cache)和數據庫級緩存(Database-Level Cache)用于提升性能。
- 查詢處理與優化:Gremlin查詢被解析、優化為一系列基礎操作。優化器會嘗試利用索引、調整遍歷步驟順序。
- 圖元素序列化:負責將頂點、邊等對象與底層存儲格式相互轉換。
- 存儲服務層(可插拔后端):
- 存儲后端:如Cassandra、HBase、Bigtable等,負責持久化圖數據(鄰接表)和事務日志。它們提供了最終的數據分布、復制與容錯能力。
- 索引后端:如Elasticsearch、Solr或Lucene,專門處理屬性索引,支持全文搜索、范圍查詢等復雜條件過濾,極大加速特定查詢。
- 協同工作流:一次查詢可能涉及:查詢解析 -> 檢查是否可利用索引(通過索引后端) -> 獲取頂點ID -> 從存儲后端讀取頂點及鄰接邊數據 -> 在內存中執行遍歷邏輯 -> 返回結果。
****:JanusGraph作為一款企業級分布式圖數據庫,通過其靈活的存儲后端架構、強大的Gremlin查詢能力以及對大規模數據的支持,在復雜關系數據管理領域占據一席之地。深入理解其存儲原理與架構設計,是進行高效數據建模、性能調優和穩定運維的關鍵。盡管學習和運維成本相對較高,但其帶來的處理超大規模關聯數據的能力,使其在特定場景下成為不可替代的解決方案。